

Facebook is making AI that can identify offensive memes
Facebook’s moderators can’t possibly look through every single image that gets posted on the enormous platform, so Facebook is building AI to help them out. In a blog post today, Facebook describes a system it’s built called Rosetta that uses machine learning to identify text in images and videos and then transcribe it into something that’s machine readable. In particular, Facebook is finding this tool helpful for transcribing the text on memes.
Text transcription tools are nothing new, but Facebook faces different challenges because of the size of its platform and the variety of the images it sees. Rosetta is said to be live now, extracting text from 1 billion images and video frames per day across both Facebook and Instagram.
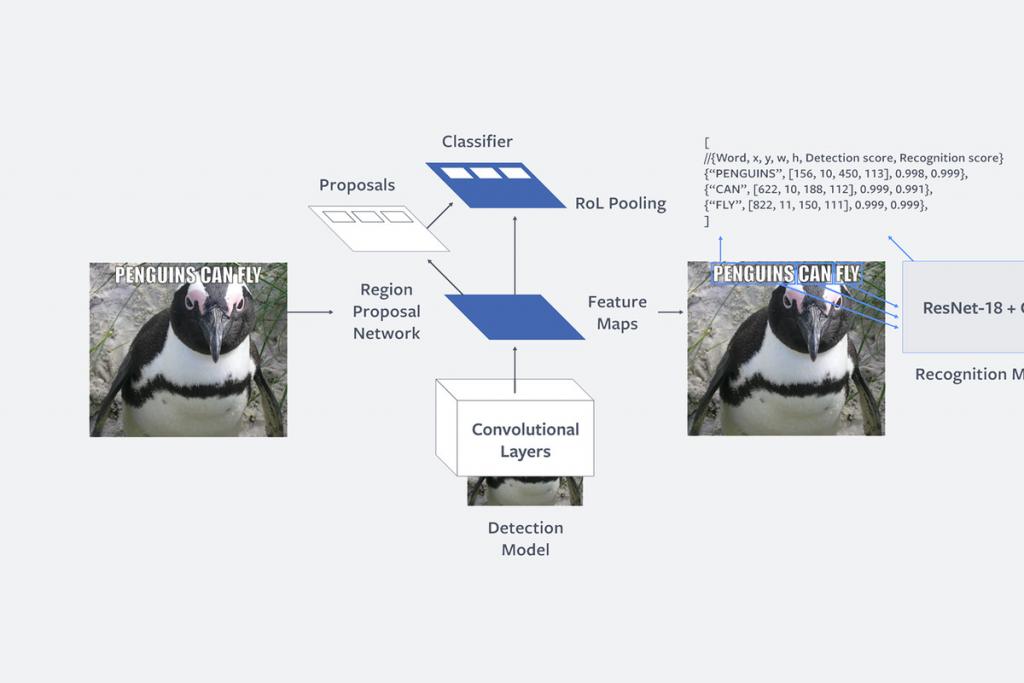
Right now, it isn’t entirely clear what Facebook is doing with the data. It’s useful for basic features like photo search and screen readers, the blog post points out. But it also sounds like Facebook is starting to put it toward much bigger goals, like figuring out what would be interesting to put in your News Feed, and, more importantly, figuring out which memes are just goofy memes and which are actually spreading hate speech or other offensive comments.
Facebook says text extraction and machine learning are being put to use to “automatically identify content that violates our hate-speech policy” and that it’s doing so in multiple languages. Given the company’s well-known moderation issues, a well-functioning system that can automatically flag potentially problematic images could be a real help.


